
Your organization’s technical debt can be a massive drain on your financial and technical resources. Like financial debt, organizations must pay interest to service technical debt. Also, like financial debt, technical debt, can also spiral out of control and become an existential threat to the organization as a whole.
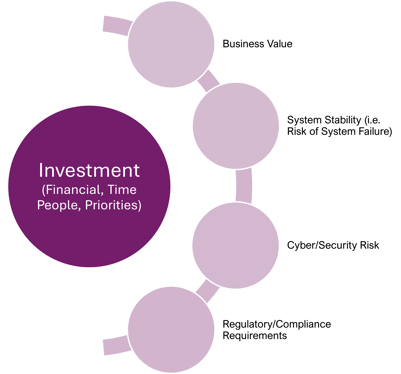 Figure 1: Balancing Investment Outcomes
Figure 1: Balancing Investment OutcomesServicing technical debt consumes corporate resources and ends up negatively impacting the corporate bottom line by diverting resources from completing initiatives that would otherwise advance the business agenda and support business objectives.
Organizations must design an “intentional” approach for dealing with technical debt and not support ambiguous objectives. The organization’s business cannot stop while technical debt is managed. A smart, intentional approach for technical debt management must balance investment with maximizing positive business outcomes that can be measured and optimized as key performance indicators (KPIs). As shown in Figure 1: Balancing Investment Outcomes, investment components include Money, Time, People and Priorities. These must be balanced out in a combination to addresses all of the following objectives:
- Business Value: Increase measurable key performance metrics for the business such as the ability to offer new customer products, improve customer satisfaction, and reduce operational costs.
- System Stability & Efficiency: Ensure corporate IT Systems are available and stable for the hours required to support business needs both internal and external to the organization. Code quality can also be improved for more efficient system resource utilization.
- Cyber/Security Risk: As cyber-risks are always emerging in the marketplace, vulnerable portions of the code base must be frequently improved and upgraded so that cyber attack vectors in the code or infrastructure are continually identified and eliminated.
- Regulatory/Compliance: Regulatory and government requirements evolve and change over time and will sometimes require enhancements to IT Systems to support requirements that legacy code cannot support.
Defining Technical Debt
Technical debt is often described as old, legacy systems that have, over time, become unstable, difficult to change and expensive to maintain. This is only part of the definition. Technical debt is incurred with every new solution or code that is promoted to production. It refers to the incremental effort required in the future resulting from choosing an expedient solution (i.e quick and dirty stuff for time to market reasons for instance) over a more robust, long term one.
It refers to the incremental effort required by the organization to manage the system landscape as a result of design decisions made to implement every IT solution the organization is running.
Technical debt accumulates with every line of code that is written by a developer or generated by an AI solution. Every IT program being deployed in the present is going to become a costly legacy system in the not too distant future. According to a 2022 Accenture study, this is a $2.41+ Trillion a year issue in the US alone. Similarly, The Wallstreet Journal has pegged this as a 1.52 trillion problem – and growing. To visualise the magnitude of this problem, consider that at the time of writing, the entire Hollywood movie industry is valued at less than $200 Billion a year.
Building Agreement on Intentional Objectives
Despite the most noble of intentions, a lot can go wrong when managing technical debt. Spending too much capital drives key resources away from initiatives that are important for meeting business metrics. Spending too little investment on managing technical debt may not provide enough value to be meaningful in the first place, and may not provide capabilities that the business requires. A balance has to be made that is appropriate for the needs of a particular business. What is certain is that organizations that do not invest in technical debt management end up losing competitive ground, pay too much to try and catchup later, or, in some cases, without any hyperbole -go out of business.
Smart, Intentional objectives
The point of being “smart” and “intentional” when managing technical debt is to ensure that the investment being made provides measurable business value in an environment where new technical debt is being created all the time. Programs that have too broad definitions can become runaway projects that take up inordinate amounts of resources and time.
 Figure 2: Smartly Tackling Technical Debt
Figure 2: Smartly Tackling Technical Debt
Figure 1: Balancing Investment Outcomes, can be divided into more detail as shown in Figure 2: Smartly Tackling Technical Debt. Figure 2 shows some of the common objectives that drive organizations to invest heavily in dealing with technical debt. Each of these topics are examined in more detail below.
Business Needs are Not Met
Keeping the figurative lights on in an organization and meeting growing business requirements are two key components of the IT Organization’s mandate. As a business grows and changes, the IT systems must also evolve to keep pace. Many need to be enhanced to support new business demands, such as a new type of transaction or a product. However, as systems age, incorporating new business functionality takes longer, costs more, or simply becomes impossible to incorporate.
Legacy System Issues
This is one of the major drivers for replacing legacy systems in their entirety. Just to keep systems running requires continual code changes and updates. Defects are discovered in production systems even years after being operational. Performance issues arise. Downtime requirements grow. The system can stop operating at times and require emergency fixes. Software obsolescence grows over time. The pool of knowledgeable and available resources to fix issues can become smaller over time as people leave, retire, or are replaced. With them leaves vital information about the systems, logic, API’s and other technical infrastructure items. Relying on documentation and information repositories are only as good as the information that was entered – and almost never complete.
Mandatory System Upgrades
Most system environments are a mix of technology solutions that are often bolted together using APIs, system calls, and ‘yes’, still batch processes. Different components in this architecture will require system upgrades or patches that are mandatory. Not doing so will result in the loss of maintenance support from the supplier and an acceleration of software obsolescence. System upgrades are mandated for a reason. They usually fix security gaps, broken functionality, or introduce new functionality. It’s never a good idea to ignore or postpone them.
System Modernization
Another major driver for eliminating technology debt is to modernize systems to support new business requirements. The end goal is the adoption of a completely new platform along with new business processes, data structures, and functionality. The legacy system needs to provide business rules, data and processes that must be at least mirrored, if not enhanced in the modernized “To Be” system.
 Figure 3: System Components
Figure 3: System Components
This approach replaces a substantial amount of technology debt and establishes a new baseline consisting of some of the components shown in Figure 3: System Components. These too can introduce technical debt in the future.
Compliance, Regulatory & Support Agreements
Regulatory and government bodies will require new functionality to be supported from time to time. This requires changes to all or usually portions of a system environment to meet these requirements. This can lead to the need to replace components of a system and this becomes an immediate priority the organization must schedule.
Vendor Lock In
Another problem many organizations begin to face over time is that of vendor lock-in. This occurs when an organization’s IT solutions are complex enough, and archaic enough that they cannot break away from a specific vendor. In this situation vendors can begin to control the relationship. Sometimes, the cost of the service is out of proportion with the value that is received. Organizations experiencing this often feel stuck. A total migration may be too costly or impractical to complete. But the current systems are costing too much to support and maintain and the vendors are becoming more costly and unable to deliver proportionate business value.
Approach for Managing Technical Debt
An iterative framework that links with standard methodologies is defined here to facilitate an “intentional” approach to managing technical debt. Figure 4: Intentional Technical Debt Management Framework shows five phases that can be executed iteratively or in a staggered fashion, as described below:
 Figure 4: Intentional Technical Debt Management Framework
Figure 4: Intentional Technical Debt Management Framework
Phase 1: Finalize Intentional Objectives
A core team of decision makers and sponsors representing Technology and the Business need to finalize the key objectives to be realized by the technical debt management initiative. Is it to meet a new regulatory requirement? Is it to stabilize a portion of the system that is resulting in business issues? Is it to open up a legacy application to allow it to support new business processes? Is it an entire modernization program that implements a new CRM and ERP? Is it to introduce AI based automation to key transactions? Being specific is important here, along with defining key performance indicators that measure value achieved.
Phase 2: Gather Software System Intelligence
Not doing this activity correctly is a major risk on any technical debt management program. Many times, the system intelligence is gathered by examining documentation, speaking with members of the project team, or by extracting technical information from asset libraries. The challenge with this approach is that the information gathered is only as good as the information that was captured. Building a plan on insufficient information will result in major issues when the initiative is running. These include missed budgets, expanding timelines, and key business functionality being missed. This can continue for a very long time and put the organization as a whole at risk.
 Figure 5: Application Context Architecture
Figure 5: Application Context Architecture
Figure 5: Application Context Architecture, shows a view of the types of ‘current’ information that should be available in ‘real-time’. Each of the connections, APIs, and nodes need to be accurate. Database connections and dependencies need to be 100% understood as well. For example, an incoming transaction may be getting split between several databases. Someone may not have documented one of the paths and this could result in major ripple impacts on the project timeline and budget to fix when it is discovered in testing – or worse in production. Observability tools and database monitoring tools can provide insights into what has happened or is happening with apps, but does not provide all dependencies that can potentially be triggered in a quarter or yearly audit for example. Nothing can be missed otherwise the plan is going to be inaccurate. The most current and relevant the information, the better will be the project outcomes.
Phase 3: Build an Informed Technology Roadmap
With the information gathered in Phases 1 and 2, a technology roadmap to deal with technical debt can be built. This plan will be accurate because of the real-time system intelligence that was gathered. It will also have the support of the project sponsors because the objectives of the program are known, agreed to, and intentional.
Phase 4. Build Your Team
With the roadmap developed, a team can be built with business and technology resources, augmented by external expertise or raw horsepower where needed. Considerations to keep other important initiatives going must factor into the decisions on who to second to the technology debt initiative on a full time basis, part time basis, or not at all. If planned properly, this initiative should still allow other key programs to continue in parallel.
Phase 5: Iteratively Execute on Roadmap (link to delivery methodology):
With the deliverables from Phases 1 through 3 completed, the team can execute the activities on the roadmap. These can be done in the context of the delivery methodology or methodologies that are standard for the organization.
Tools to Gather the Right System Intelligence
As shown in the Technical Debt Management Framework, a prerequisite to a successful technology debt initiative is to gather intelligence about the affected software system environment. This is vital to building an informed debt management strategy and is best accomplished by using a tool that automatically scans a software system environment and builds artifacts using real data – not information entered into data repositories. The latter suffers from outdated or missing information.
 Figure 6: Portfolio Snapshot
Figure 6: Portfolio Snapshot
For example, CAST Highlight, as shown in Figure 6: Portfolio Snapshot, automatically maps entire software portfolios. The tool scans source code repositories, analyzes all applications for tech debt density, obsolescence, cloud maturity, intellectual property exposures, and so on. It then maps the empirical findings against subjective data, e.g., business criticality and recommends the best path forward across the entire software codebase. This provides an effective checklist that the project management team can use to prioritize their work and to ensure that nothing is forgotten.
For large and complex applications one can leverage a tool like CAST Imaging. Figure 7: Displaying Structural Flaws, shows a pictorial produced by the tool that provides a deeper look inside the software system. The tool maps the internal structures, applies sematic analysis, and pinpoints the few pieces of code that most impact the business, such as structural flaws outlined in ISO 5055.
 Figure 7: Displaying Structural Flaws
Figure 7: Displaying Structural Flaws
 Figure 8: Well Constructed Loop with Bad System Performance
Figure 8: Well Constructed Loop with Bad System PerformanceTraditional Tools Only Provide Part of the Picture
Local code analyzers, which analyze syntax, could generate a list of issues with each unit inside an application, and even prioritize what they see as the most critical issues, at the unit level. This still leaves thousands of tasks to be managed by teams and suppliers to resolve, resulting in thousands of person-days of effort, A local code analyzer may flag a piece of code for optimization due to performing a table scan instead of using an index. While technically the code isn’t perfect, understanding the context may tell us that it operates on a reference table with only a few rows. Optimizing the code only shaves off a fraction of a millisecond from the response time. Why address such seemingly 'severe' code issues if in context they are not severe at all.
Conversely, a local code analyzer may greenlight a piece of code, yet its immediate context renders it potentially dangerous in terms of user experience. A common example of that is when a small piece of code, nested within a loop, makes a call to a distant REST service or a remote database as shown in Figure 8: Well Constructed Loop with Bad System Performance.
Here’s another example. While a single remote call may be acceptable, making 1,000 consecutive calls, with time-consuming roundtrips, especially when far from the data source, could severely hinder the system. There are numerous situations where the individual unit quality will be seen as “good”, but it does contain technical debt negatively impacting application behavior. Thus, its necessary to analyze the unit of code not in isolation but in the context of the whole system, considering the flows from the user input layer to the business logic, APIs, frameworks, data access layers, down to the database. So, how is this done? Couldn’t a team understand the context by looking at the code and talking to architects?
 Figure 9: Application 'Internals' map of a rather small application. Generated by CAST Imaging
Figure 9: Application 'Internals' map of a rather small application. Generated by CAST Imaging
This can be like finding a needle or two in a haystack. The challenge is that even a small application with 30,000 LoC harbors thousands of interdependencies between its internal code units. See the lines in Figure 9: Application ‘Internals’ map of a rather small and simple application, where each dot is a code unit. This is a map of a rather small and simple application.
Most organizations have much more complex applications that require a strong tool-set to provide real-time and complete information about the inner workings and connections of the software landscape.
 Figure 10: Map of the Inner Workings of a Mid-Size Application with 300,000 LoC
Figure 10: Map of the Inner Workings of a Mid-Size Application with 300,000 LoC
The situation gets exponentially worse for a typical mid-sized application with merely 300,000 LoC. In this case, it is comprised of 41,000 units and has numerous interdependencies. See (if you can) the lines in Figure 10: Map of the Inner Workings of a Mid-Size Application with 300,000 LoC. Now, imagine the staggering complexity of a core system ten times the size, with 3,000,000 LoC or much more. No wonder the adage “don’t touch it, if it works” has become so popular in the world of software engineering.
Clearly, grasping the entire application context needs automation. Currently, the fastest way to automate that knowledge extraction is to rely on technology that performs semantic analysis of each code unit and its interactions with all other units. This means using technology that understands what the unit does in the context of the surrounding architecture. It maps the thousands of units illustrated above and creates a ‘digital blueprint’ of the application’s inner workings. It’s like using an ‘MRI’ to see the connections between the ‘brain, nerves, and muscles’ inside each of the critical applications. Upon completing such analysis, a knowledge base is created capturing all interconnections. Then, specific structural quality rules can be applied (see ISO 5055), to spotlight problematic patterns in context. Semantic and contextual analysis is what for example CAST Imaging does, among others such as Coverity for C++ code.
The 8% approach
While many organizations may be tempted to do a complete system replacement, it’s better to focus on completing a selective replacement after finding the problematic places in the code. That is the crux of what is called the 8% approach.
 Figure 11: A 30,000-foot view of a portfolio of 300 Customer Applications, generated by CAST Highlight
Figure 11: A 30,000-foot view of a portfolio of 300 Customer Applications, generated by CAST Highlight
Consider a Fortune 500 organization that operates a vast environment of off the-shelf packages supporting back-office functions and over 300 custom applications that together amount to 50 million lines of code (LoC) for core business operation. To get started, first set aside the commercial off-the-shelf software, and focus on custom software code. First, identify the custom applications with high concentration of technical debt and cross-reference that against business criticality. This can be fully automated and done within a week using software mapping and intelligence technology from CAST. That involves combining code-level technical debt insights (X-axis) with a rapid survey to evaluate business criticality (Y-axis). The size of each bubble (application) reflects the number of LoC in Figure 11: A 30,000-foot view of a portfolio of 300 customer applications.
Then, the team can focus on the most important business applications that also exhibit high density of technical debt, while ignoring those with minimal impact, viewing them as 'good enough' for now. The map in Figure 10 indicates that the area for deeper investigation, in the top right corner, includes only 5 or 6 applications. The team may also explore several other mission-critical applications in the top left corner, where four sizable bubbles representing 2 million LoC each likely hide a fair amount of technical debt, even if the density per line of code is lower.
Mapping the software landscape allows the team to drastically scope down further investigation. Still, in this example, the team is facing a total of 12 million LoC to assess and a lot of technical debt to contend with. Picking the targets According to Gartner (“Measure and Monitor Technical Debt With 5 Types of Tools”), poor software structures have an unbounded negative impact on quality and delivery speed. This observation rests on the phenomenon succinctly articulated by MIT’s Dr. Richard Stoley in his seminal research with the Consortium for Information and Software Quality, Carnegie Mellon University, and the Object Management Group. Dr. Stoley finds that “the same piece of code can be of excellent quality or highly dangerous”, which depends on the context. It depends on how the individual units are structured together. He goes on to state that “basic unit-level errors constitute 92% of all errors in source code. However, these numerous code-level issues account for only 10% of the defects encountered in production. Conversely, poor software engineering practices at the technology and system [architecture] levels make up just 8% of total defects, yet they result in 90% of the significant reliability, security, and efficiency issues in production.” This raises the question: how do we identify the 8% that matter most within an extensive codebase, 12 million LoC in this example, and resolve those defects most efficiently?
It is usually not necessary to replace all the code related to technical debt entirely. This means that organizations may, in some cases, be spending more time and money than they need to be to address this important issue.
Conclusion
Being intentional with the approach to software system modernization is the key to a having a successful initiative versus having one that goes massively overbudget or experiences significant project delays.
Trying to eliminate technical debt from A to Z or address all code quality issues at the individual unit level is not an effective strategy. Business Objectives must first be defined. Then current and relevant software or system intelligence is needed to drive out an effective plan. Not having this information is an ineffective, costly and dangerous approach.
The key to unwinding technical debt is to map out the critical applications ripe with technical debt, then identify the few pieces of code inside that have the most significant negative impact on the business. That all sounds like common sense. What’s crucial for identifying the 8% of flaws that matter most is understanding the internal application context. Semantic analysis technologies can automate the discovery. As MIT Fellow Dr. Soley pointed out, the same piece of code can be perceived as either good or bad depending on its surrounding context. Taking that into account will address your technical debt most efficiently and bring the desired business outcomes withing the least amount of time. And of course, applying the 8% approach proactively, before any code changes make it into production, can reduce the expense of having to deal with bad tech debt to begin with.
It is clear that maintaining effective software solutions to solve business needs is a continuous journey of understanding/identifying focus areas, getting up to date software intelligence, and then building and executing in the most efficient way possible.
About the authors
Sanjiv Purba is an award winning, hands-on Transformational CIO/CTO and Board Member with over 25 years of progressive Technology and Business experience within Industry and Consulting Organizations. He works with C-Suite & Corporate Boards of mid-to-large sized companies who want to digitally transform their business and surgically leverage IT solutions such as AI, Payments Modernization, ERP, CRM, HRIS & Data Analytics to maximize share price through effective implementation and ongoing Operations. Sanjiv has written over 20 books and hundreds of articles for such publications as The Toronto Star & The Globe & Mail. He can be contacted at Sanjiv.purba@deliberit.com.
Vincent, the founder of CAST, is a passionate entrepreneur who believes "you can’t manage what you don’t see." He pioneered the software intelligence field, enabling application owners to make fact-based decisions, control risks, accelerate modernization, cloud optimization, and the overall pace of software engineering. He can be contacted at v.delaroche@castsoftware.com.






SHARE